
Foundation Model Development Cheatsheet
This cheatsheet aims to make it easier for new community members to understand our resources, tools, and findings. We emphasize good practices, understanding limitations, and responsible use of these resources.
Foundation Model Training Overview
Download Foundation Model Development Cheatsheet
A Review of Tools & Resources
[Authors][Arxiv ID]
This cheatsheet serves as a succinct guide, prepared by foundation model developers for foundation model developers.
Development Insights & Best Practices
Note
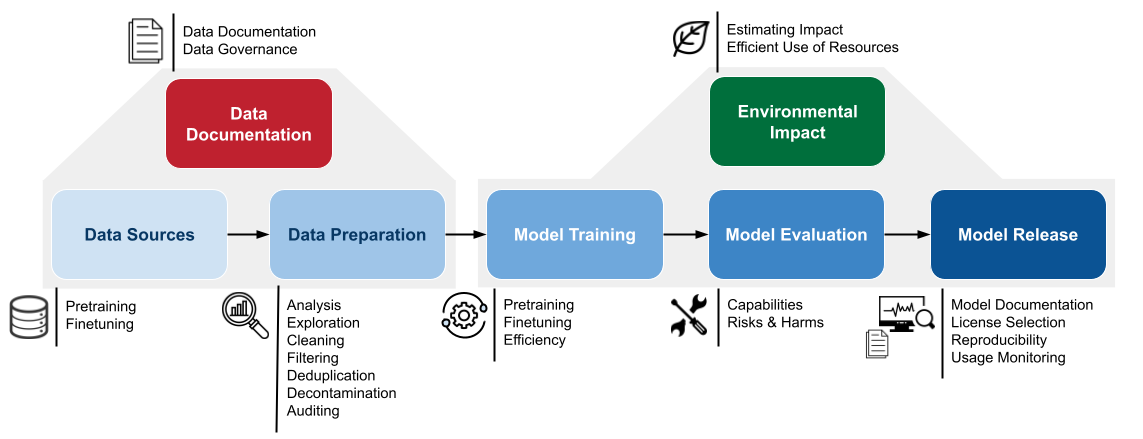
These are the different parts of the AI development process, and we have a corresponding cheatsheet section on each.
Pretraining data provides the fundamental ingredient to foundation models—including their capabilities and flaws. Finetuning data hones particular abilities of a model, or in the case of instruction finetuning or alignment training, improves the models general usability and helpfulness while reducing potential harms.
More data is not always better. It is essential to carefully source data, and manually inspect it to ensure it fits the goals of your project.
Dataset selection includes many relevant considerations, such as language and dialect coverage, topics, tasks, diversity, quality, and representation.
Most datasets come with implicit modifications and augmentations, from their selection, filtering, and formatting. Pay attention to these pre-processing steps, as they will impact your model.
Finetuning data can hone some capabilities or impair others. Use catalogs to support an informed selection, and prefer well-documented to under-documented datasets.
The most appropriate datasets may not exist for a given set of tasks. Be aware of the limitations of choosing from what is available.
Tools for searching and analysing can help developers better understand their data, and therefore understand how their model will behave; an important, but often overlooked, step of model development.
Data cleaning and filtering can have an immense impact on the model characteristics, though there is not a one size fits all recommendation. The references provide filtering suggestions based on the application and communities the model is intended to serve.
When training a model on data from multiple sources/domains, the quantity of data seen from each domain (data mixing) can have a significant impact on downstream performance. It is common practice to upweight domains of “high-quality” data; data that is known to be written by humans and has likely gone through an editing process such as Wikipedia and books. However, data mixing is an active area of research and best practices are still being developed.
Removing duplicated data can reduce undesirable memorization and can improve training efficiency.
It is important to carefully decontaminate training datasets by removing data from evaluation benchmarks, so their capabilities can be precisely understood.
Data documentation is essential for reproducibility, avoiding misuse, and helping downstream users build constructively on prior work.
We recommend to start the documentation process early, as data is collected and processed.
For datasets with multiple stakeholders, or derived from community efforts, it is important to appropriately proactively organize its access, licenses, and stewardship.
The foundation model life-cycle consists of several stages of training, broadly separated into pre-training and fine-tuning.
Decisions made by developers at any stage of training can have outsized effects on the field and the model’s positive and negative impacts, especially decisions made by well-resourced developers during the pre-training stage.
Developers should be thoughtful about the effects of train-time decisions and be aware of the trade-offs and potential downstream effects prior to training.
Due to the large economic and environmental costs incurred during model training, making appropriate use of training best practices and efficiency techniques is important in order to not waste computational or energy resources needlessly.
Training and deploying AI models impacts the environment in several ways, from the rare earth minerals used for manufacturing GPUs to the water used for cooling datacenters and the greenhouse gasses (GHG) emitted by generating the energy needed to power training and inference.
Developers should report energy consumption and carbon emissions separately to enable an apples-to-apples comparisons of models trained using different energy sources.
It is important to estimate and report the environmental impact not just of the final training run, but also the many experiments, evaluation, and expected downstream uses.
It is recommended, especially for major model releases, to measure and report their environmental impact, such as carbon footprint, via mechanisms such as model cards (see Section 3).
Model evaluation is an essential component of machine learning research. However many machine learning papers use evaluations that are not reproducible or comparable to other work.
One of the biggest causes of irreproducibility is failure to report prompts and other essential components of evaluation protocols. This would not be a problem if researchers released evaluation code and exact prompts, but many prominent labs (OpenAI, Anthropic, Meta) have not done so for model releases. When using evaluation results from a paper that does not release its evaluation code, reproduce the evaluations using an evaluation codebase.
Examples of high-quality documentation practices for model evaluations can be found in Brown et al. (2020) (for bespoke evaluations) and Black et al. (2022); Scao et al. (2022); Biderman et al. (2023) (for evaluation using a public codebase).
Expect a released model to be used in unexpected ways. Accordingly, try to evaluate the model on benchmarks that are most related to its prescribed use case, but also its failure modes or potential misuses.
All evaluations come with limitations. Be careful to assess and communicate these limitations when reporting results, to avoid overconfidence in model capabilities.
Release models with accompanying, easy-to-run code for inference, and ideally training and evaluation.
Document models thoroughly to the extent possible. Model documentation is critical to avoiding misuse and harms, as well as enabling developers to effectively build on your work.
Open source is a technical term and standard with a widely accepted definition that is maintained by the Open Source Initiative (OSI) (Initiative, 2024). Not all models that are downloadable or that have publicly available weights and datasets are open-source; open-source models are those that are released under a license that adheres to the OSI standard.
The extent to which “responsible use licenses” are legally enforceable is unclear. While licenses that restrict end use of models may prevent commercial entities from engaging in out-of-scope uses, they are better viewed as tools for establishing norms rather than binding contracts.
Choosing the right license for an open-access model can be difficult. Apache 2.0 is the most common open-source license, while responsible AI licenses with use restrictions have seen growing adoption. For open-source licenses, there are several tools that are available to help developers select the right license for their artifacts.
Frameworks for monitoring and shaping model usage have become more prevalent as policymakers have attempted to constrain certain end uses of foundation models. Several approaches include adverse event reporting, watermarking, and restricting access to models in limited ways. Consider providing guidance to users on how to use your models responsibly and openly stating the norms you hope will shape model use.
Click on the corresponding development section to view foundation model resources.
Data Sources
Data Preparation
Data Documentation and Release
Model Training
Environmental Impact
Model Evaluation
Model Release and Evaluation

Assembled by open model developers from AI2, EleutherAI, Google, Hugging Face, Masakhane, MIT, MLCommons, Princeton, Stanford CRFM, University of California Santa Barbara (UCSB), Univesity College London (UCL) and University of Washington (UW).
Frequently Asked Questions (FAQ) About Foundation Models
A foundation model is a type of large language model (LLM) or other AI model that has been trained on a massive amount of data. These models have a wide range of capabilities, from generating realistic text to translating languages and creating different forms of creative content.
Building a foundation model is a complex task. The cheatsheet has sections on "Data Search, Analysis, & Exploration" tools to help you find and understand training data, as well as "Model Training" sections on repositories and efficiency techniques.
The quality and diversity of your data greatly impact your model. "Pretraining Data Sources" and "Finetuning Data Catalogs" sections of the cheatsheet explain factors to consider like language coverage, data source mixes, and the importance of clear documentation.
Yes, the computational power needed for training foundation models has a significant carbon footprint. The cheatsheet includes an "Environmental Impact" section with tools and methodologies to estimate and responsibly manage this impact.
The cheatsheet covers responsible AI practices extensively. Key points include: Thorough model documentation ("Model Documentation" section), Evaluating risks and potential harms ("Model Evaluation" sections), Careful license selection for your model ("License Selection" section), and Potentially monitoring model usage ("Usage Monitoring" section).
The cheatsheet is actively maintained and encourages community contributions. It's designed to be a starting point, with many sections linking to in-depth resources and repositories.